This is the second in the series of posts about the Web Viewer Integrations Library.
In the previous post, I introduced to you the Web Viewer Integrations Library, a labor of obsession and passion around the web viewer object. It has been a lot of fun to put together, and I am glad to be able to share it.
In this post, I want to review the data structure of this library, how the file is set up to make these integrations happen. In another post, we will examine the actual file and see its many features, but here we will simply focus on how the file is built.
A Typical Web Page
A typical web page consists of many files hosted on some web server. Figure 1 shows what a typical web page might contain. Web pages usually start off with an index.html page. Inside this page are links to other files that contain the CSS or the Javascript.
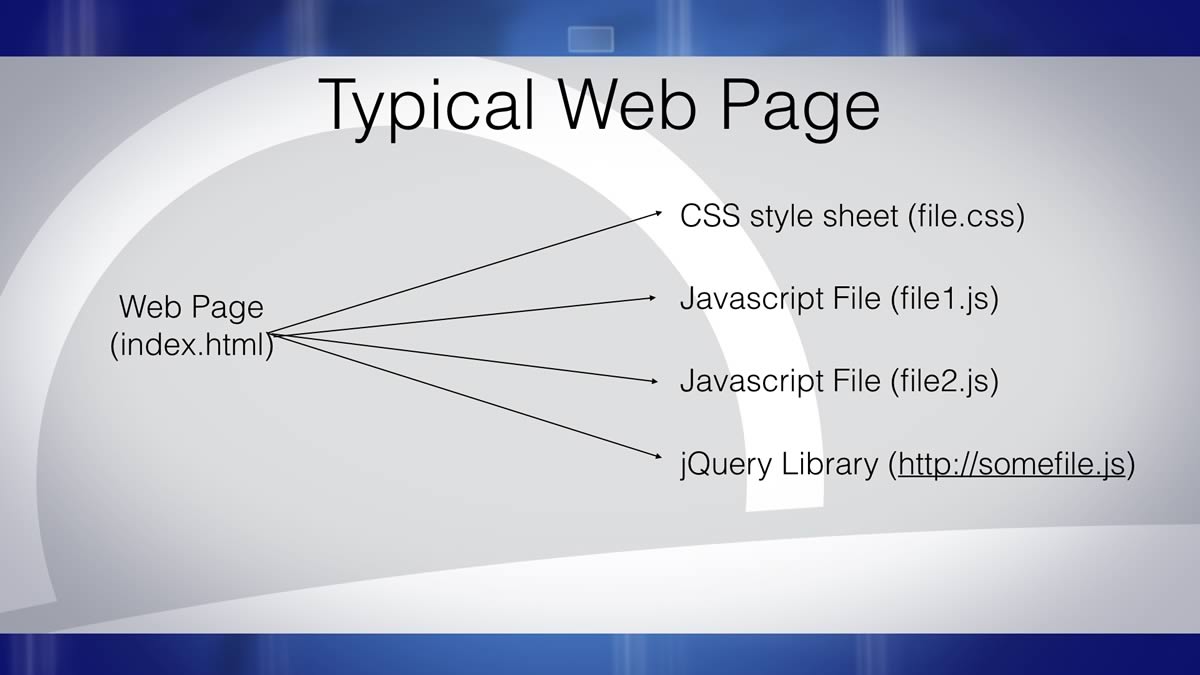
According to the web organization W3, web code should be separated into separate files with links in the index.html page for many reasons:
- Efficiency of code: the entire web page loads faster when each page has a chance to load into the computer’s memory on its own rather than one file loading everything. Additionally, it is easier to find a specific section in smaller files.
- Ease of maintenance: If a developer needs to update the look of the web page, she only needs to open the styles.css page.
- Accessibility: Adaptive devices such as screen readers read the text from the HTML file only. It skips over the files with the CSS or the Javascript.
- Device Compatibility: An HTML page with no style information inside can be easily adapted depending on the device. If the page is viewed on a phone, the HTML page can access a CSS file with styles designed specifically for that device.
- Web Crawlers/Search Engines: Google and other search engines read through the index.html page for the content. Finding content allows your site to be returned in these engines.
The last reason is simply that it is good practice. Standards-aware web developers separate content, style and functionality.
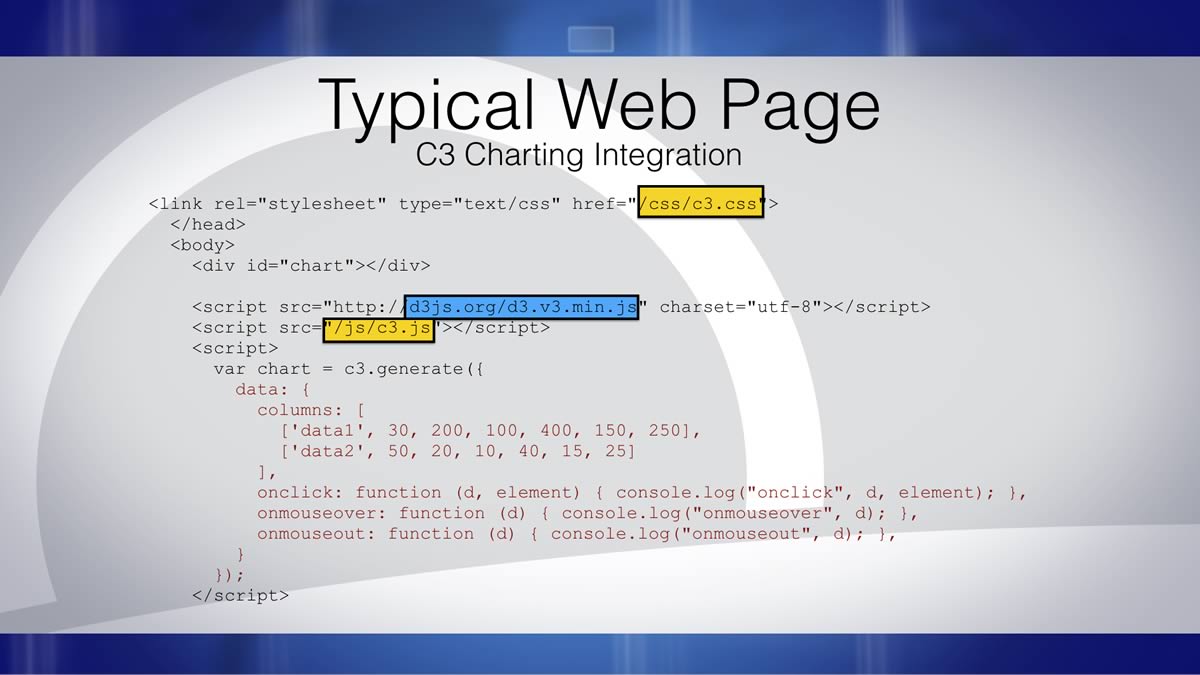
In the code for the C3 Charting Integration shown in Figure 2, there are four files that make this integration happen: the index.html page and three external sources, highlighted in the code. In this case, the files CSS and Javascript files (highlighted in yellow) are stored on some computer local to the index.html page. Further, this C3 Charting library needs to access an external source, shown in blue.
Adapting for FileMaker
In FileMaker, we don’t have quite this flexibility; It is a bit more difficult to work with multiple files needed for an integration. So we need to come up with a different solution. Let’s take a moment to look at those options.
Inside the Web Viewer Setup
Sometimes developers choose to put all the code for an integration (the index.html, the css file and all the Javascript files) inside the web viewer itself into one long piece of text. This method has two major disadvantages:
- A calculation dialog’s limit is 30,000 characters.
- It is very difficult to find and modify some particular part of the integration such as the background color of one element or the functionality of one Javascript function.
Inside a Text Object
Other people put the all the text into a text object that is hidden on the layout. It does give you a bit easier access to the code and has no length restriction, but it is still difficult to modify and you always have to modify the text in layout mode.
The Chosen Solution
In this library, I’ve chosen to place what would be separate web files into separate fields. We start with an HTML field, I call it the “HTML template” The CSS code is in a field called “CSS1”, and the Javascript files are in fields named “JS1”, “JS2”, and so on.
In order to incorporate these separate fields into the web page’s code, the content of the the HTML fields needs to be combined together into one calculation. I am using placeholder text, such as “**CSS1**” in the HTMLTemplate field to then be replaced by the content of the HTML::CSS1

Thus all the code needed for an integration is found in the fields. This library contains 22 integrations, so there are 22 records. In the effort to standardize these integrations into this file, I’ve created three CSS fields, three Javascript fields, and three data fields. These are filled in with whatever code is needed, and in the proper place in the HTML template field, the placeholder text is set. The integrations presented here nicely fit within this model.
There are some advantages to this method.
- An integration will work online or offline because all the code is stored locally in fields of a record.
- The text placed inside each field most likely will not come close to the 10,000,000 character limit per text field.
- Specific to this library, It is very easy to export an integration from here and place it into your custom app. As we’ll discuss in a later post, exporting an integration record is very easy.
The fact that the code is stored locally is an advantage and a disadvantage. Locally-stored code, as we said above, doesn’t require outside resources to run, but the code is static and won’t change automatically. If the jQuery library updates from say version 3.1.1 to 3.1.2, the integrations stored locally will not automatically be able to use the new features of the new version. We would have to manually go find the new version of the jQuery library and import it into the correct fields. However, this is little trouble; if our integration is working satisfactorily, there may be no need to get the newest version.
This FileMaker Web Viewer Integrations library is set up in a way that allows for an efficient implementation for any custom app.
In the next post we will take a look at the features of this file as you use it to manipulate and export an integration.
Get the Demo File
Next Post
If you have any questions, please reach out to our Carafe team.
These are the other blog posts and videos that go into further detail about this file and how to integrate these into your own custom apps: