Are you struggling with poor FileMaker Server performance that’s hindering your FileMaker application? K’you can help remediate these challenges.
Why a Queue?
I am staring at an AWS S3 bucket with just over a quarter of a million objects in it. I need the metadata for those objects in FileMaker.
Obviously, I can make API calls from FileMaker to AWS and get that info since everything in AWS is an API. I absolutely love this, but that’s another topic.
The issue is not how to get the data; it’s processing that data in a reasonable amount of time.
When you call the AWS S3 functionality to list all the objects in a bucket, it will, by default, return those in batches of 1,000. The worst way to process these is to process each batch in sequence. That would take the most amount time. Ideally, we should have a way to process some of these batches in parallel and cut down the total time.
Leveraging a NodeJS Microservice
Because AWS has a powerful and easy to use JavaScript SDK, I typically choose to interact with the AWS APIs through a NodeJS microservice. Don’t worry, I won’t make you read through how to set all of that up. That is not the point of this article. Instead, I want to share with you my journey on building that parallel processing.
Preparing Data for Processing
It suffices to understand how I get the data into FileMaker ready for processing. But remember, this is not the crucial part:
FileMaker calls the microservice, telling the name of the AWS S3 bucket to get the object information from. It also passes along a batch identifier (a FileMaker UUID).

That is it as far as the FileMaker Pro script is concerned. The NodeJS microservice just replies with an “accepted” message. FileMaker does not need to wait on the result.
The NodeJS microservices uses the built-in functionality of the AWS SDK to ask for a list of all the objects. For each chunk of 1,000, the microservice calls the FileMaker Data API to create a record. This record stores the return-delimited list of 1,000 object info items and the batch UUID it got from FileMaker at the start of the process.
When the microservice is done with all the AWS data, it creates one more record in FileMaker through the Data API to indicate that it is done.
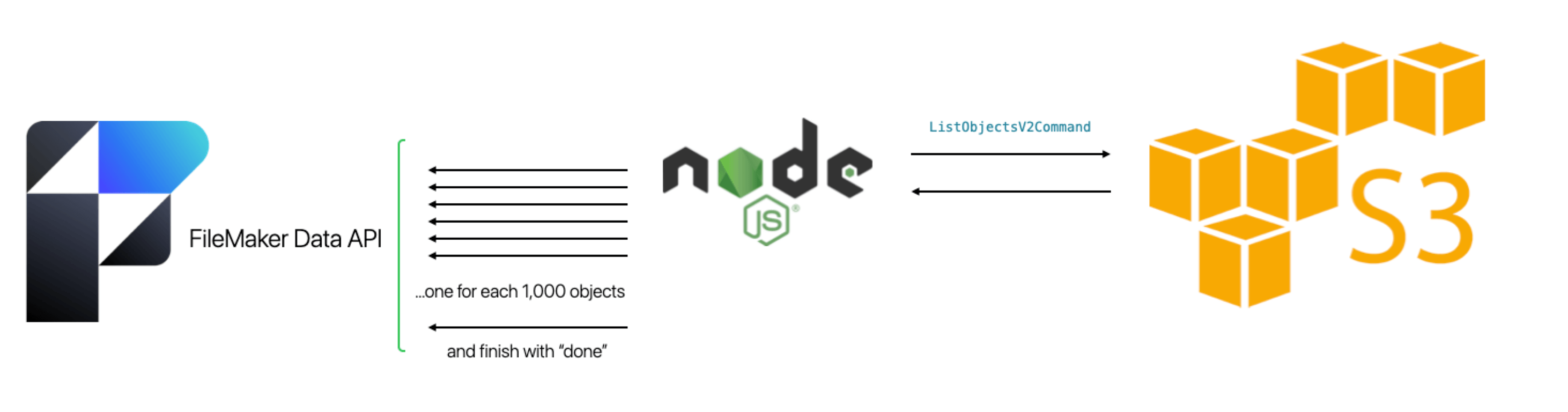
This part is very fast. This creates 250 records in FM in the span of about 45 seconds, about 5 records per second. This is infinitely faster than having FileMaker make 250 calls itself to the AWS S3 APIs.
Processing the Queue
Now this is where the story really begins. I am sitting on 250 records, each with a list of 1,000 objects that I need to parse out into individual records. My original script that started the process is not aware of these records. It hung up the phone with the microservice a long time ago.
The calls to the Data API run a script after the record gets created. This script only parses out the UUID from the data that the microservice sent. I can therefore quickly find all the records that belong to the same batch.
The script also checks for the “done” record. When it detects that record, the script knows that all data records have been created and the microservice is done. We can get to the processing part.
Remember that at this point, that script is running in the Data API engine. We do not want to keep that Data API session around for long. REST calls are meant to be short-lived. We do not want to tie up the microservice that is making the call to the Data API.
The Data API script will call a queue controller script through Perform Script on Server (PSoS) with the “don’t wait” option toggled on. This hands off control over processing the data to the FMSE (FMSASE) script engine.
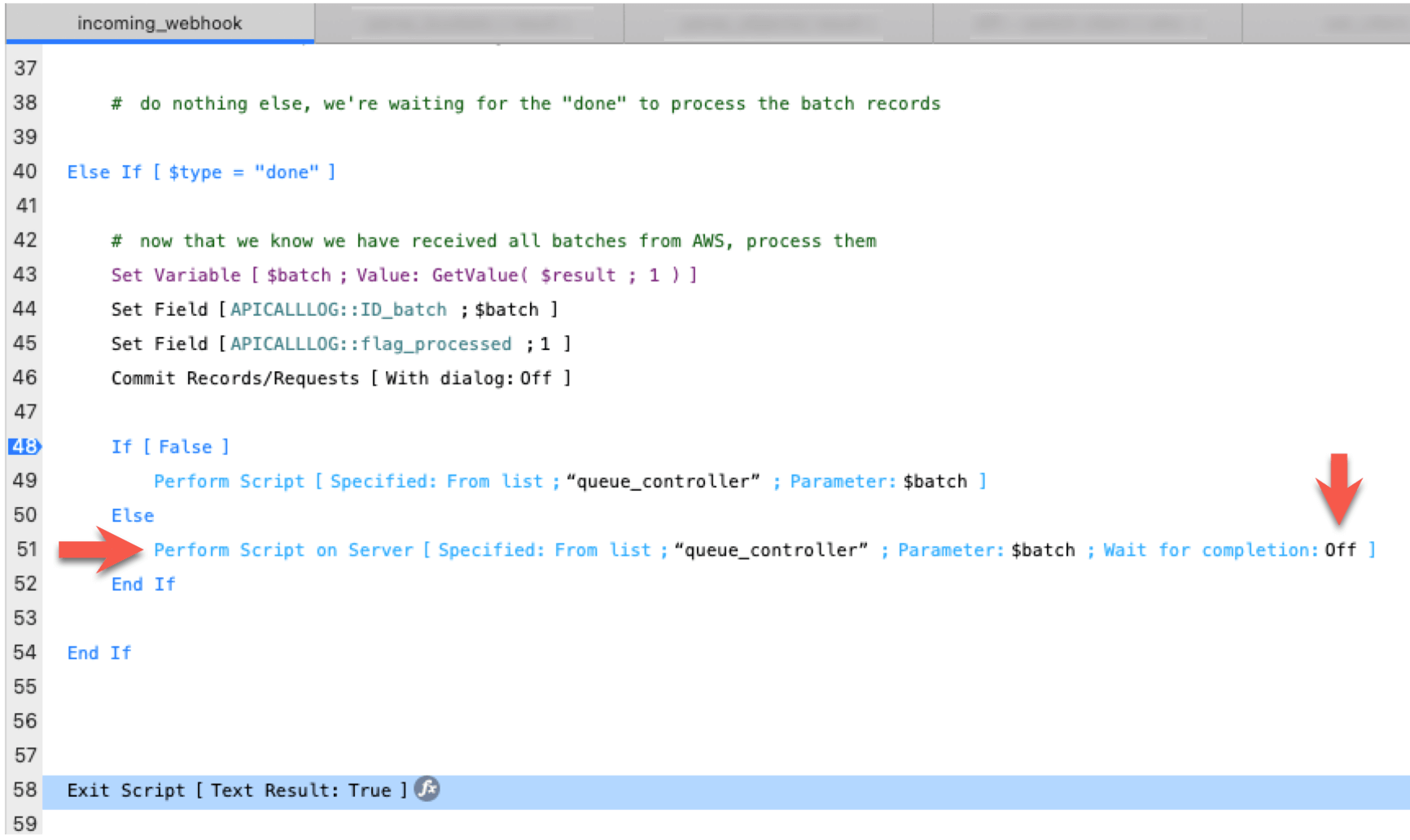
(The IF[ False ] branch is there so that I can step through the code when debugging).
The $batch script parameter holds the UUID of our batch. The queue controller script can therefore easily find all 250 records created by the microservice.
Processing in Parallel
But remember that we want to process these in parallel to speed up the overall process and improve FileMaker Server performance. So how are we going to spin up multiple PSoS sessions from here? And how many?
Let’s tackle the how many first. There is a fine balance here because the server may busy already and/or may not have a lot of spare resources to take on extra load. Out of the box, FileMaker Server supports 100 concurrent PSoS sessions. You can bump that number up to 500. But I would urge caution here. Spawning too many at the same time can make the whole process take longer instead of shortening it. I’m going with a max of 10 sessions. Our controller script will need to check how many sessions the FMSE script engine currently has running and only spawn new sessions up to the max allowed by us.
Protecting Performance for Connected Users
And this is where the Friendly part comes in. Because the server may have to accommodate other PSoS sessions from functionality elsewhere in the hosted apps, I want my routine to only use PSoS slots that are available, up to 10. If FileMaker Server has four other PSoS sessions, my routine will spawn six. Then, when those six are done or any of the four sessions that do not belong to me finish, my routine will spawn more. That keeps this functionality from completely taking over the server and affecting the connected users in a bad way. Your FileMaker Server performance gets a boost.
How? We are going to use both the Data API and the Admin API for this. The Admin API can tell us at any time how many sessions the FMSE scripting engine is running. (That’s the scripting engine used by server-side schedules and PSoS sessions).
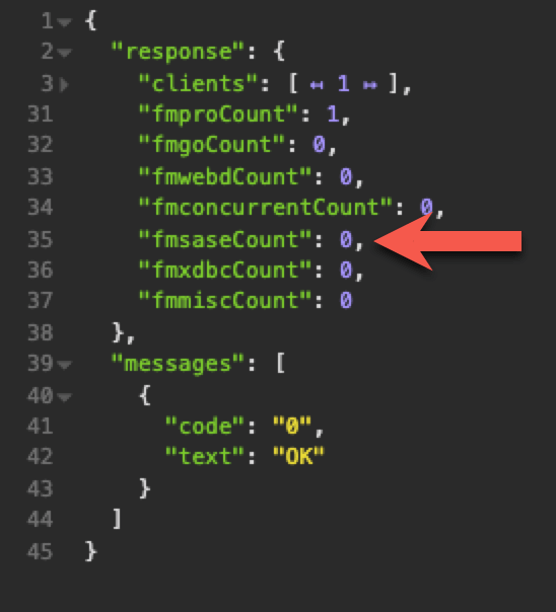
The Data API is our middleman to be able to spawn new PSoS sessions. By default, a PSoS session cannot create a new PsoS session.*
Queue Controller
The queue controller script will run server-side and keep an eye on what records still need to be processed. It is responsible for figuring out how many processing PSoS sessions to spawn and when.
It knows what batch to work with by the parameter it was given (line 19).
In the config area, you get to decide how many maximum PSoS sessions you want (all of them, not just yours), on line 25.
On line 24, you set the time you will wait between checking how many PSoS sessions there are and spawning new ones if there is spare capacity. In this case: every 1 second.
Lines 30-34 creates a Data API session that will be kept alive for the duration . With this, we can call the Data API to create new PSoS sessions for us.
Lines 39-42 creates an Admin API session. By default, FileMaker Server only allows 5 admin sessions. If we called the Admin API every second without maintaining a session, we would bump against that limit very quickly.
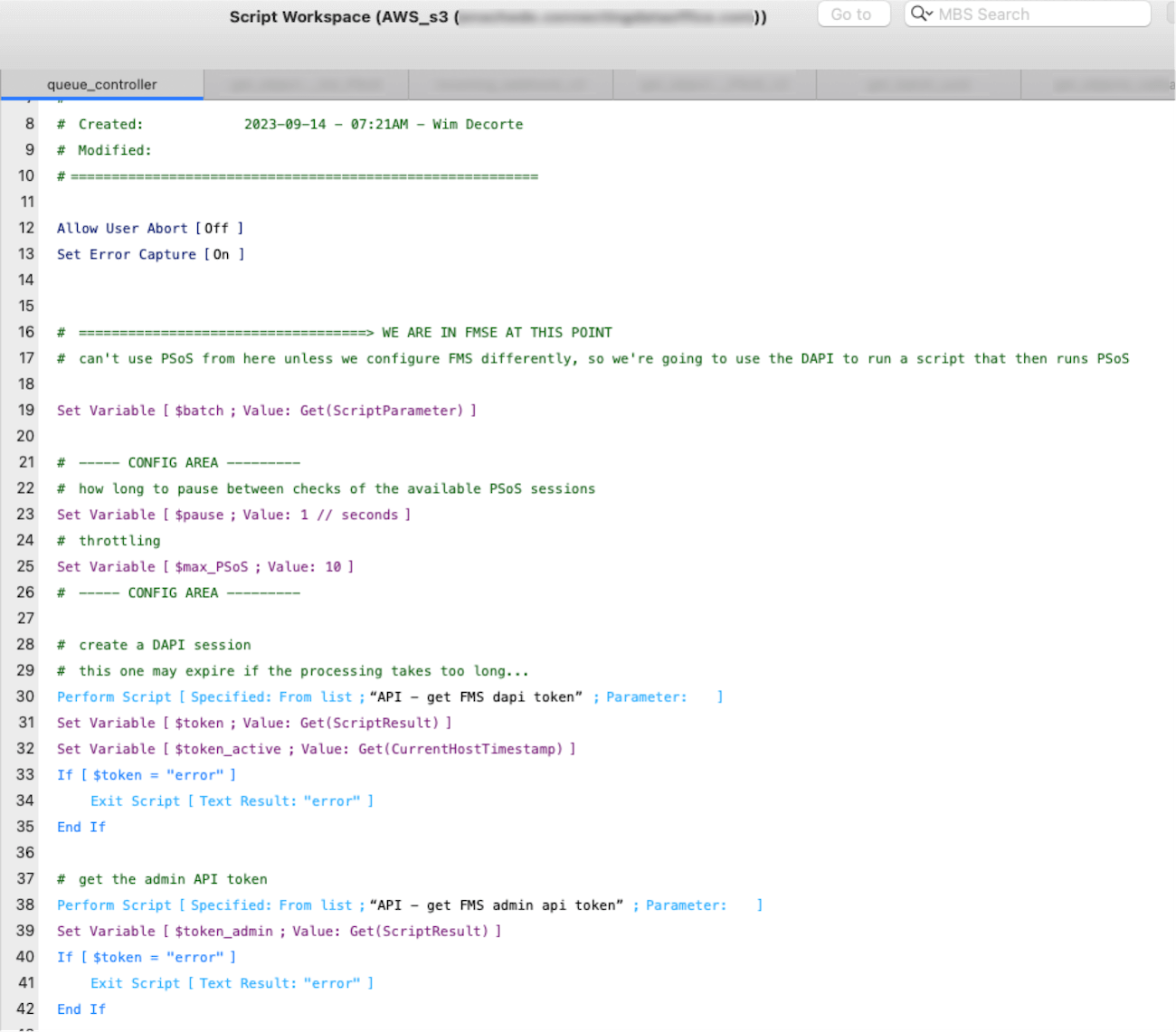
The rest of the controller script is a loop. Every second, it will use the Admin API to ask server how many FMSE sessions there are. If there are fewer than 10 (our self-imposed maximum), it will spawn new ones up to the max we allow. Line 50 gets us the list of unprocessed records on every iteration.
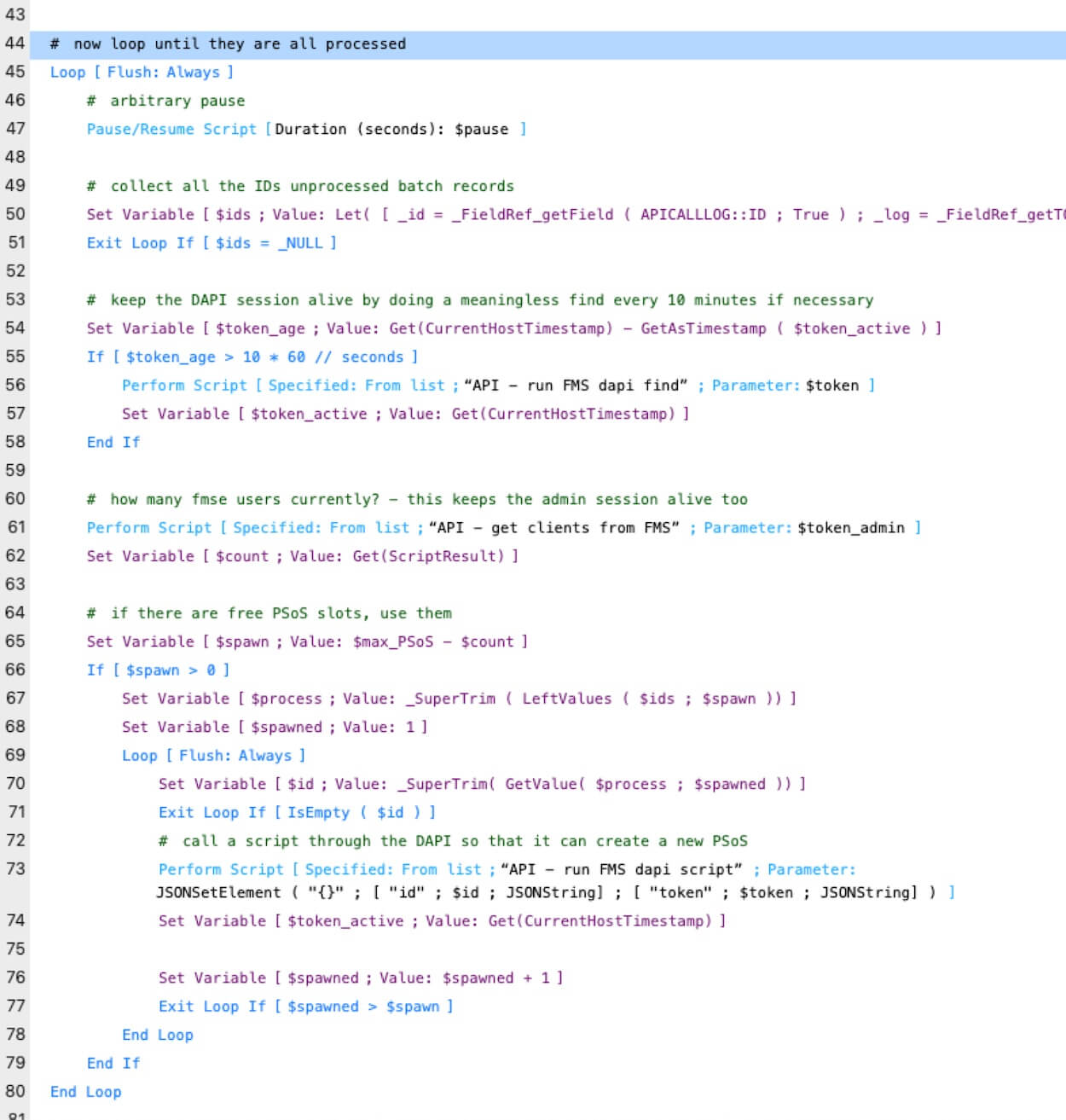
Avoiding Timeouts That Impact FileMaker Server Performance
Both the Admin API and Data API time out after 15 minutes of inactivity. For the Admin API we have no worries about that. We call it every second to check on the number of client sessions.
But the processing scripts may take a long time. If there are no new sessions to spawn within 15 minutes, the Data API might time out. That is why on lines 53-58 we do a lightweight but meaningless search on a 1-record table. This keeps the Data API alive if it hasn’t been used in more than 10 minutes. We set the $token_active at the start when we get the token plus reset it after each Data API call. If the processing scripts take less than 10 minutes, we never have to do this tickle call.
Queue Processor Spawner
Line 73 of the queue controller’s loop is the call to the Data API so the Data API script engine can create a new PSoS session. It is just a passthrough script and it passes on the primary key of the record that the PSoS session needs to process.

Queue Processor
This is where the parsing business logic is. Its function is not relevant except that it should flag the record it has handed. This communicates the status to the queue controller.
Time Saved / Don’t Assume
As a test, I ran a PSoS script to process all records one after the other. It took just over an hour or about 14 seconds per record. That varies a bit depending on the rest of the server activity.
By using the parallel queue, I was able to cut this down by half to just over 30 minutes. The time to process an individual record with its 1,000 entries actually takes longer. The added activity and how the server needs to time-slice its available processor time across more tasks slows everything down. But we’re still done sooner than if we did them all sequentially.
Completing Jobs in Half the Time
We are trading individual processing time for parallelism. Each job takes longer, but since we’re doing more jobs at the same time instead of one at a time, we cut down the aggregate time to just over 30 minutes. We are done in half the time it would take to do the whole job sequentially.
And we are doing it in such a way to be mindful of the other activities on the server. We’re being flexible, friendly to our neighbours, and helpful. Just like we strive to be.
Throttling to Avoid Maxing Out on Concurrent Jobs
There is a point at which asking your server to handle a certain number of concurrent jobs is going to slow everything down. FileMaker Server performance is impacted to the extent that you lose all benefit from trying to do things in parallel.
That is why throttling through the $max_PSoS variable in the queue controller script is so important. You will get the maximum performance by not exceeding what your server is capable of handling. A lot of this comes down to how many processor cores your server has. If you have few cores, then setting $max_PSoS low will make the total job faster, not slower. That may seem counter-intuitive, but it is entirely logical.
Depending on your server’s hardware and the nature of the FileMaker work that needs to happen, there is no guarantee that doing the jobs in parallel will be faster than doing them in sequence. But when the opportunity is there, the nature of the work fits, and the resources are available, K’you is a good approach to keep in mind.
Further Improving Your FileMaker Server Performance
Our FileMaker consulting team leverages tools like K’you to expand upon FileMaker functionality. We build custom business applications for our clients with things like exceptional FileMaker Server performance in mind. If you’d like to extend your solution’s capabilities and empower your business to do more, our team can help. Contact us to talk to a FileMaker developer today.